
[ RDBMS ]
Os arquivos de dados podem ser associados a somente um banco de dados
e, uma vez criados, não podem ter o seu tamanho alterado. Um ou
mais arquivos de dados formam uma unidade lógica de armazenamento
de dados chamada tablespace. Os arquivos de dados são lidos sempre
que necessário durante as operações feitas em um banco
de dados e seus dados são mantidos sempre que possível em
memória, para minimizar o I/O.
Dados de Usuário e Dados de Sistema
Dois tipos de dados ou informações são armazenados
nos arquivos de dados associados a um banco de dados: dados de usuários
e dados do sistema.
Os dados do usuário são os dados de seu aplicativo, com todas as informações a ele relevantes. Essa é a informação que sua instituição armazena no banco de dados. (informação de agências/clientes, informação de pesquisas, informações financeiras).
Os dados de sistema são a informação que
o banco de dados precisa para gerenciar os dados de usuário
e a si mesmo. (informações sobre as tabelas: campos da tabela,
tipo de informação; quantidade de espaço físico
que os objetos do banco de dados ocupam, informações sobre
usuários: nomes, senhas, privilégios; informações
sobre os arquivos de dados: número, localização, hora
da última utilização; integridade referência
entre objetos).
Tablespaces
Como um banco de dados é um conjunto de arquivos de dados, é
muito importante que você entenda como um banco de dados Oracle agrupa
esses arquivos. Ele faz isso sob a proteção de um objeto
de banco de dados chamado tablespace. Antes de inserir dados dentro
de um banco de dados Oracle, primeiro você deve criar um tablespace
e depois uma tabela dentro deste tablespace para conter os dados, então,
uma tablespace é usada para agrupar outras estruturas lógicas
relacionadas entre si.
O tamanho combinado dos arquivos de dados que formam uma tablespace ditam a sua capacidade de armazenamento. A combinação da capacidade de armazenamento de todas as tabespaces que formam um banco de dados forma a capacidade total de armazenamento desse banco de dados.
Uma tablespace pode estar acessível (on-line) ou não (offline), geralmente permanece on-line, disponível para os usuários. Entretanto para algumas tarefas administrativas ou em algumas situações especiais, é possível deixá-las offline.
Portanto, os dados de um banco de dados Oracle estão armazenados
logicamente em tablespace e fisicamente nos arquivos de dados associados
as tablespaces correspondentes. As tablespaces são usadas para:
Nomes de tablespace e conteúdo
Em um típico banco de dados existem algumas tablespaces padrões,
mas lembre-se os nomes aqui discutidos são apenas uma cinvenção;
não é obrigatório que o DBA da sua instituição
os utilize. A função principal dos tablespaces é
ajuda-lo a organizar seu banco de dados.
Tablespace System
O tablespace system é uma parte obrigatória de todo banco
de dados Oracle. É onde o Oracle armazena todas as informações
necessárias para o gerenciamento, como os nomes dos tablespaces
e o que os arquivos de dados de cada tablespace contêm.
Tablespace Temp
O tablespace temp é onde o Oracle armazena todas as suas tabelas
temporárias. É o quadro branco ou papel de rascunho do banco
de dados. No caso de um banco de dados muito ativo, você pode ter
mais de um tablespace temporário.
Tablespace Tools
O tablespace tools é onde você armazena os objetos de
banco de dados necessários para suportar as ferramentas usadas com
o banco de dados, como o SQL*PLUS, assim como qualquer aplicativo Oracle
o SQL*PLUS precisa armazenar tabelas no banco de dados.
Tablespace Users
O tablespace users contém informações pessoais
dos usuários.
Tablespace de Dados e de Índice
Daqui em diante, tudo pode acontecer. Em algumas instalações,
você verá nomes de tablespace como: DAT01, DATA02 e DATA3,
que representa diferentes locais para conter dados; em outras, poderá
ver o nome fazendo referência a projetos como : prossiga, doutorado,
mestrado, etc.
Tablespace de Reconstrução
Todos os banco de dados Oracle precisam de um local para armazenar
informações a desfazer. Esse tablespace, que contém
seus segmentos de reconstrução, normalmente se chama rollback
(rbs). Uma das principais razões para você usar um sistema
de gerenciamento de banco de dados como o Oracle é sua capacidade
de recuperar transações incompletas ou abortadas como parte
da funcionalidade do núcleo.
Registros de Redo
Além dos arquivos de dados associados a um tablespace, o Oracle
tem outros arquivos de sistema operacional associados, chamados de registro
de redo on-line. Outro nome comum para os registros de redo é registros
de transação. Eles são arquivos especiais de sistema
operacional em que o Oracle resgistra todas as alterações
ou transações que acontecem no banco de dados. Quando são
feitas mudanças no banco de dados, essas alterações
ocorrem na memória. O Oracle manipula essas alterações
na memória por razões de desempenho. Uma E/S de disco e mil
vezes mais lenta do que uma ação na memória. Como
uma cópia de todas as transações é sempre gravada
nos registros de redo on-line, o Oracle pode levar tempo gravando no arquivo
de dados original as mudanças nos dados que ocorreram na memória.
Finalmente, a última cópia da alteração nos
dados é gravada no arquivo de dados físicos. Como todas as
transações são gravadas nos registros de redo on-line,
o banco de dados sempre pode ser recuperado a partir desses registros de
transação. É obrigatório que todo banco de
dados Oracle tenha pelo menos dois registros de redo on-line.
Como funciona os registros de redo
Os registros de redo funcionam de modo circular. Digamos que você
tenha um banco de dados com dois registros de redo on-line, log1 e log2.
À medida que as transações criam, eliminam e modificam
os dados no banco, elas são gravadas primeiro no log1. Quando o
log1 está cheio, ocorre uma troca de registro. Então, todas
as novas transações são gravadas no log2. Quando o
log2 fica cheio, ocorre outra troca de registro e novamente as transações
são gravadas no log1.
Isso nos leva a discução de como o banco de dados Oracle roda no modo ARCHIVELOG ou NOARCHIVELOG, e isso tem uma correlação direta com os registros de redo on-line.
Modo ARCHIVELOG: Recuperabilidade completa
Quando um banco de dados está rodando no modo ARCHIVELOG, todos
os registros de redo de transação são mantidos. Isso
significa que você tem uma cópia de cada transação
executada no banco de dados; assim, mesmo os registros de redo funcionando
de modo circular, é feita uma cópia do registro de redo antes
de ele ser sobrescrito. No caso de o banco precisar trocar antes de a cópia
ser feita, Oracle será congelado até que essa ação
tenha terminado. O Oracle não permitira que a transação
antiga seja sobrescrita até ter uma cópia dela. Tendo uma
cópia de todas as transações, o banco de dados pode
agora proteger você contra todos os tipos de falha, incluindo erros
de usuário ou falha de disco. Esse é o modo mais seguro de
rodar um banco de dados.
Modo NOARCHIVELOG
Quando um banco de dados está rodando no modo NOARCHIVELOG (o
padrão), os registros de redo antigos não são mantidos.
Como nem todos os registros de transação são mantidos,
você só está protegido de eventos como falta de energia
(não se esqueça que o preechimento de um registro o faz ser
trocado, quando ele circula em torno do original, a informação
anterior é perdida).
Arquivos de Controle
Todo banco de dados deve ter pelo menos um arquivo de controle, embora
seja altamente recomendável que você tenha dois ou mais. Um
arquivo de controle é um arquivo muito pequeno que contém
informações importantes sobre todos os arquivos associados
a um banco de dados Oracle. Os arquivos de controle mantêm a integridade
do banco de dados e ajudam a identificar quais registros de redo são
necessários no processo de recuperação. Antes que
o banco de dados possa começar a rodar, ele passa pelo arquivo de
controle para determinar se está em forma aceitável, se alguma
falha for detectada durante a inspeção o banco não
inicializa até que o problema seja corrigido.
Programas
Agora é hora de discutirmos os programas, que vamos chamar de
processos, sempre que um programa é inicializado no banco de dados,
ele se comunica com o Oracle através de um processo. Existem dois
tipos de processos Oracle que você deve conhecer:
Processos do usuário (cliente)
Os processos de usuário trabalham para você, solicitando
informações dos processos de servidor. Exemplo de processo
de usuário são o Oracle Forms, Oracle Reports e o SQL*PLUS.
Processos de servidor
Os processos do servidor pegam os pedidos dos processos de usuário
e se comunicam com o danco de dados. Através dessa comunicação,
os processos de usuário trabalham com os dados do banco de dados.
Processos de Suporte de Banco de Dados
Conforme foi visto, os processos de servidor pegam os pedidos dos processos
de usuário e se comunicam com o banco de dados em nome dos processos
de usuário. Vamos discutir sobre um conjuto especial de processos
de servidor que ajuda o banco de dados funcionar.
Escritor de banco de dados
O escritor de banco de dados (dbwr - database wuiter) é um processo
obrigatório que registra os blocos da dados alterados nos arquivos
do banco de dados. Ele é um dos dois únicos processos que
permitem escrever nos arquivos de dados que constituem o banco de dados
Oracle.
Ponto de controle
Ponto de controle (chpt - checkpoint) é um processo opcional.
Quando os usuários estão trabalhando com o Oracle, eles fazem
os pedidos de procura de dados. Os dados são lidos doas arquivos
do banco de dados e colocados em uma área de memória onde
os usuários podem vê-los. Eventualmente, alguns desses usuários
fazem alterações nos dados, que devem ser regravados nos
arquivos de dados originais. Você deve estar lembrado dos registros
de redo e de como eles registram todas as transações. Quando
o registro de redo se alteram, ocorre um ponto de controle. Quando essa
troca acontece, o Oracle vai na memória e escreve as informações
dos blocos de dados sujos de volta no disco. Além disso, ele notifica
o arquivo de controle a respeito da troca de registro de redo.
Escritor de registro
O escritor de registro (lgwr - log write) é um processo obrigatório
que escreve entradas de redo em registros de redo. Não esqueça
que os registros de redo são uma cópia de cada transação
que ocorre no banco de dados. Isso é feito para que o Oracle possa
se recuperar de vários tipos de falha. Além disso, como uma
cópia de cada transção é escrita em um registro
de redo, o Oracle não precisa despender seus recursos constantemente,
escrevendo alterações de dados de volta nos arquivos de dados
imediatamente. Isso resulta em um desempenho melhor. O escritor de registro
é o único processo que escreve nos registros de redo. Ele
também é o único processo de um banco de dados Oracle
que lê os registros de redo.
Monitor de sistema
O monitor de sistema (smon - system monitor) é um processo obrigatório
que executa qualquer recuperação necessária na inicialização.
No modo de servidor paralelo, ele também pode realizar recuperação
de um banco de dados falho em outro computador.
Monitor de processo
O monitor de processo (pmom - process monitor) é um processo
obrigatório que efetua a recuperação de um usuário
falho do banco de dados. Ele assume a identidade do usuário falho,
liberando todos os recursos do banco de dados que o usuário estava
segurando, e reconstrói a transação abortada.
Arquivador
O arquivador (arch - archiver) é um processo opcional. Conforme
vimos anteriormente, os registros de redo são escritos de modo seqüencial.
Quando um registro é preenchido, há uma troca para o próximo
registro de redo disponível. Quando você está rodando
o banco de dados no modo ARCHIVELOG, ele faz uma cópia do registro
de redo. Isso é feito para que, quando o banco de dados voltar para
esse registro de redo, haja uma cópia do conteúdo desse arquivo
para propósitos de recuperação. Essa é a tarefa
do processo arquivador.
Bloqueio
O bloqueio (lck - lock) é um processo opcional. Quando você
estiver rodando o banco de dados Oracle no modo de servidor paralelo, verá
vários processos lck. No modo de servidor paralelo, esses bloqueios
ajudam os bancos de dados a se comunicar.
Recuperador
O recuperador (reco - recoverer) é um processo opcional visto
apenas quando o banco de dados está rodando a opção
distribuída do Oracle. A transação distribuída
é a em que duas ou mais posições dos dados podem ser
mantidas em sincronismo.
Estrutura de Memória
O Oracle usa dois tipos de estrutura de memória: a área
global de sistema (SGA) e a área global de programa (PGA). Os processos
do cliente e do servidor comunicam-se através da estrutura de memória.
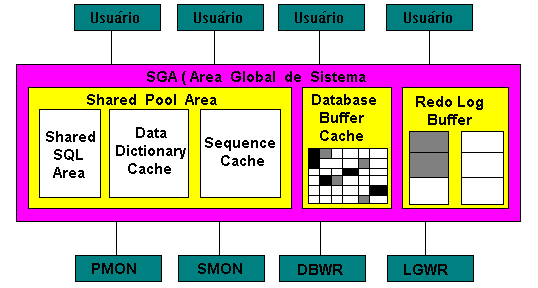
Área Global de Sistema
A área global de sistema (SGA - system global area) é
um local na memória em que o banco de dados Oracle armazena informações
pertinentes sobre si. Ele faz isso na memória, pois ela é
o modo mais rápido e eficiente de permitir que os processos se comuniquem.
Essa estrutura de memória é acessível para todos os
processos de usuário e de servidor. Como a SGA é o mecanismo
pelo qual os diversos processos de cliente e de servidor se comunicam,
é importante que você entenda seus vários componentes.
Shared Pool Area e seus Buffers
A estrutura de memória compartilhada chamada shared pool area
contém informações usadas para executar os comandos
SQL. é formada pelos seguintes buffers:
Shared SQL Área
Este buffer contêm:
Data dictionary Cache
Este buffer contêm linhas com as informações do
dicionário de dados.
Sequence Cache
E por fim, este buffer contêm informações sobre
os geradores de número sequenciais utilizados pelos usuários.
Data Dictionary Cache
Uma cache de dicionário contém linhas do dicionário
de dados. O dicionário de dados contém todas as informações
que o Oracle precisa para se gerenciar, como quais usuários têm
acesso ao banco de dados Oracle, quais objetos de banco de dados eles possuem
e onde esses objetos estão localizados.
Database Buffer Cache
A cache de buffer de dados é onde o Oracle armazena os blocos
de dados usados mais recentemente do banco de dados. Quando você
coloca informações no banco de dados, elas são armazenadas
em blocos de dados. A cache de banco de dados é uma área
da memória na qual o Oracle coloca esses blocos de dados para que
um processo de usuário possa vê-los. Antes que um processo
de usuário possa ver os dados, estes devem residir inicialmente
na cache de buffer de dado. Há um limite físico para o tamanho
da cache de buffer de dados. Assim, quando o Oracle a preenche, ele deixa
os blocos mais quentes na cache e retira os mais frios. Ele utiliza o algoritmo
LRU para esta finalidade.
Redo log Buffer
Antes que qualquer transação possa ser gravada no registro
de redo, primeiro ela deve residir no buffer de registro de redo. Essa
é uma área da memória separada para esse evento. Então,
periodicamente o banco de dados descarrega esse buffer nos registros de
redo on-line.
Instância
Todas as vezes que o Oracle é inicializado, um grupo de buffers
de memória denominado System Global Area (SGA) é alocado
e alguns processos que permanecem em background são inicializados.
A combinação desses buffers de memória e dos processos
em background forma uma instância Oracle. Para que o banco de dados
não se confunda, cada instância é identificada pelo
que é conhecido como identificados de sistema (SID - system identifier).
Na maioria dos computadores UNIX, ele é definido pela variável
"ORACLE_SID".
Referência :
| <= |